
某天我進去了Mobile01論壇,看到了一堆關於網路的文章,絕大部分都是投訴和各種吐槽(無誤)。而這些文章裡面少不免都會有一些traceroute的資料附上,然後我每一次看到樓下的那些大大竟然錯誤的解讀這些traceroute其實還真的有一個衝動想去糾正他的。在這篇文章我會介紹一些重要的觀念和用一些例子去告訴traceroute裡面到底可以蘊含怎麼樣的訊息。
註:本文涉及術語和一堆奇奇怪怪的圖解,新手看不太明白的可以留言,我會盡量回答的。
我會告訴大家這一些東西:
- 到底traceroute是什麼
- 如何解讀路由器DNS名稱
- 認識網路延遲
- 非對稱路由
- 多重路徑
- MPLS 和 traceroute 的關係
Traceroute到底是什麼?
Traceroute是一個用來找出網路路徑的小工具,他雖然簡單,不過他對於解決網路問題還蠻實用的。我們要知道在網路上資料是以封包的形式傳送的。在每一個封包裡面會有一個標頭告訴所有處理這些封包的路由器到底要怎麼傳送。在眾多標頭資訊裡面,TTL(Time To Live)是一個很特別的標頭,告訴封包到底要經過多少個路由器還沒到達終點才會被丟棄。
在traceroute裡面,程式首先會把一個封包傳送去指定的目的地,並把封包的TTL標頭值設定為1,這樣當封包經過第一個路由器的時候就會被丟棄,路由器丟棄封包的時候同時也會對發出封包的IP傳送一個ICMP TTL Exceeded的訊息告訴你,並會附上該路由器的IP位置。重複這個步驟並不斷的增加TTL數值,直至封包到達目的地的時候,目的地會傳送一個ICMP Destination Unreachable(不要問我為什麼到了目的地還要傳Unreachable封包)的封包,告訴你已經到達目的地。以下是一個圖形化的流程:
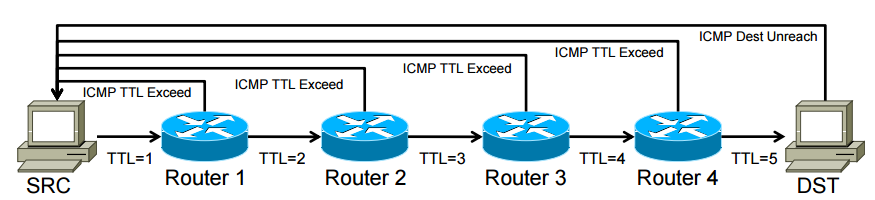
多一點點資訊
- 每一次traceroute通常都會傳送超過一個測試封包
- 大部分情況下都會在每一次增加TTL的時候傳送三次測試封包(每一次增加TTL的結果我們叫他做一個節點)
- 會在每一個節點出現該數量的延遲值,或是如果節點不回應會出現
- 並不是所有Traceroute程式都會用同一類型的測試封包
- 例如*nix通常使用UDP,Windows用ICMP,一些工具甚至是使用TCP
那麼traceroute每一個節點的延遲值到底是怎麼計算出來的?
- 電腦紀錄傳送測試封包的時間
- 電腦紀錄接收封包的時間
- 兩者相減,獲得延遲值
在傳遞測試封包的過程當中,路由器並不會對封包做時間計算,他們只是很簡單的把ICMP訊息傳回去來源。值得留意的是,traceroute紀錄的延遲值是封包來回的延遲值。雖然traceroute只會顯示你去目的地的路由,不過如果封包傳回去來源的路有不同的話,所測量的延遲值都會受影響的。
從路由層級理解

從以上的例子我們可以看到TTL=1的封包從連入介面進入了路由器,由於TTL在路由器內會遞減,於是封包的TTL=0。根據規範,路由器必須向來源傳送ICMP TTL Exceed的訊息,至於ICMP標頭的封包來源就是路由器連入介面的IP位置了(就是封包是從路由器連入介面傳送回去來源的)。於是,traceroute的輸出會是172.16.2.1 10.3.2.2。(不過你知道嗎,這行為其實不是正確做法。根據RFC 1812的規範,ICMP封包應該是在路由器的輸出介面送出去才對,只是如果真的這樣做的話traceroute的結果就會不準確了)
如何解讀路由器的DNS名稱?
這部分應該算是最重要的部分了。要正確看懂traceroute,這個技巧是最有用也是最重要的。透過解讀路由器的DNS名稱我們可以從名字中獲得很多有用的資訊,例如:
- 路由器的地理位置
- 路由器的介面類型和速度
- 路由器的類型和作用
- 網路邊界和不同網路之間的關係
通常要理解網路問題,知道路由器的地理位置是很重要的。知道了路由器的地理位置以後,我們可以辨認不正確/非最佳的路由、可以理解網路的互連關係、或是索性找出問題所在點(例如找出高延遲的路由節點)。通常地說,路由器的地理位置通常會以以下的代碼去表示:
- IATA機場代碼
- CLLI代碼
- 城市簡稱
- 有時候你不知道那到底是什麼代碼的時候,你只好去猜測了

IATA機場代碼
IATA機場代碼由於是國際通用的,所以通用範圍很廣,而且IATA機場代碼都會用在一些較大型的網路交會點。以下是一些例子:
- 洛杉磯 = LAX
- 矽谷 = SJC
- 東京 = NRT
- 香港 = HKG
- 台北 = TPE
有時候,我們並不會用正規的機場代碼去標籤路由器的地點,這尤其是在該城市有多個機場的時候適用,又或是正規機場代碼根本不是一看就會的時候我們也會這樣做。例如美國紐約市有三個機場,分別是JFK、LGA和EWR。你可以一眼就看得出這到底是什麼地方嗎?並不是對吧?所以在紐約的路由器通常都會在他們的名稱以NYC去表示他們的位置。又例如弗吉尼亞州南部的機場代碼是IAH,首都華盛頓的機場代碼是DCA,不過我們通常都會統稱WDC。
CLLI代碼(Common Language Location Identifier)
這個代碼我找了很久都找不到中文名字… 這一個代碼是一個很有歷史的代碼,在很久以前由Telecordia公司編制和發售,通常是由電話公司採用的。例子有 HSTNTXMOCG0 和 DLLSTXRNDS1。不過現在ISP不是電話公司,所以通常只會採用這種代碼的首六個字母。例子有 HSTNTX(休斯頓) 和 DLLSTX(達拉斯)。
這種代碼在北美洲的確是一種標準,而且在一些有較多網路節點的大型網路比較常見。不過一旦離開了北美洲,就已經不再通用了,有一些ISP還會為了保持格式一樣在為其他不在北美洲的城市創作這一些代碼(NTT就是一個常見例子),例如荷蘭的阿姆斯特丹會變成 AMSTNL 又或是東京會變成 TOKYJP 這樣子。
隨意改名字
有時候在ISP裡面工作的人在打混的就會索性為自己的網路節點隨意改一個名字。以下是一些例子:
- 芝加哥
- IATA機場代碼:ORD,MDW
- CLLI代碼:CHCGIL
- 隨意改的(只是一個例子):CHI
- 多倫多
- IATA機場代碼:YYZ,YTC
- CLLI代碼:TOROON
- 隨意作出來:TOR
- 東京
- IATA機場代碼:NRT,HND
- CLLI代碼:TOKYJP
- 隨意作的:TOK,TYO
- 台北
IATA機場代碼:TPE- CLLI代碼:TAPITW
- 隨意作出來的:TAP,TAI
通常這一些隨意作出來的代碼都是以容易閱讀作為編寫的宗旨,不過他們真的完全沒有標準可言。
常用位置代碼列表
| 城市 | IATA機場代碼 | CLLI代碼 | 其他代碼 |
| Ashburn, VA | IAD | ASBNVA | ASH, WDC, DCA |
| Atlanta, GA | ATL | ATLNGA | |
| Chicago, IL | ORD, MDW | CHCGIL | CHI |
| Dallas, TX | DFW | DLLSTX | DAL |
| Houston, TX | IAH | HSTNTX | HOU |
| Los Angeles, CA | LAX | LSANCA | LA |
| Miami, FL | MIA | MIAMFL | |
| Newark, NJ | EWR | NWRKNJ | NEW, NWK |
| New York, NY | JFK, LGA | NYCMNY | NYC, NYM |
| San Jose, CA | SJC | SNJSCA | SJO, SF, SV |
| Palo Alto, CA | PAO | PLALCA | PA, PAIX |
| Seattle, WA | SEA | STTLWA | |
| Amsterdam, NL | AMS | AMSTNL | |
| Frankfurt, GE | FRA | FRNKGE | |
| Hong Kong, HK | HKG | NEWTHK | HGK |
| London, UK | LHR | LONDEN | LON, LDN |
| Madrid, SP | MAD | MDRDSP | |
| Montreal, CA | YUL | MTRLPQ | MTL |
| Paris, FR | CDG | PARSFR | PAR |
| Singapore, SG | SIN | SNGPSI | SGP, SNG |
| Seoul, KR | ICN, GMP | SEOLKO | SEL, SEO |
| Sydney, AU | SYD | SYDNAU | |
| Taipei, TW | TPE | TAIPTW | TAP, TAI |
| Tokyo, JP | HND, NRT | TOKYJP | TOK, TYO |
路由器介面種類
絕大部分的ISP都會把路由器介面資訊順便放上去路由器DNS名稱上面,以方便他們去除錯。不過這些資訊未必一定是最新的,因為很多大型網路都採用自動產生的DNS名稱。雖然是這樣,這也可以幫助你去辨認這一個路由節點到底是什麼類型和速率的,再強一點甚至可以猜測ISP到底在用什麼路由器。以下是一個例子:
xe-11-1-0.edge1.NewYork1.Level3.net
上面的例子取自美國最大的網路Level3。我們可以像以下般拆解這名稱:
- NewYork1 代表這一個路由節點在紐約,1代表機房編號。
- 這一台路由器是一台Border Router
- xe-#-#-#是一個 Juniper 路由器的 10Gbps 連接,它最少有十二個插槽。
- 這一台路由器應該是最小 40Gbps / 插槽 的,因為它的第一個插槽就已經是 10Gbps 的 PIC。
- 這一台一定是 Juniper MX960,沒其他的 Juniper 路由器符合此規格。
都說了從名字都可以看到很多資訊的啦!以下是一個常見的路由器介面格式:
| 介面類別 | Cisco IOS | Cisco IOS XR | Juniper |
| Fast Ethernet (100Mbps ) | fa#-# | fe-#-#-# | |
| Gigabit Ethernet (1Gbps) | gi#-# | gi#-#-#-# | ge-#-#-# |
| Ten Gigabit Ethernet (10Gbps) | te#-# | te#-#-#-# | xe-#-#-# |
| SONET / SDH | pos#-# | pos#-#-#-# | so-#-#-# |
| T1 (1.544Mbps) | se#-# | t1-#-#-# | |
| T3 (44.736Mbps) | t3-#-#-# | ||
| Ethernet Bundle (Link Aggregation) | po# / port-channel# | be#### | ae# |
| SONET Bundle (Link Aggregation) | posch# | bs#### | as# |
| IP Tunnel | tu# | tt# / ti# | ip-#-#-# / gr-#-#-# |
| ATM | atm#-# | at#-#-#-# | at-#-#-# |
| VLAN | vl{#VLAN ID#} | {interface type}#-#-#-#.{#VLAN ID#} | {interface type}-#-#-#.{#VLAN ID#} |
(注意:這些只是常用命名規則,有時候可能不適用)
路由器類別 / 用途
有時候知道路由器的類別或是用途也會有用途。不過每一個網路都不同,用的路由器命名規則也不一樣,甚至有時候網管自己都不一定嚴謹的跟隨自己的命名方法。通常而言,我們可以透過猜測上下文來估計路由器的用途來獲得該路由器基本的類別/用途。
- 核心路由器 - cr, ccr, core, bb, gbr, ebr
- 邊緣路由器 - br, bbr, border, edge, ir, igr, peer
- 客戶路由器 - ar, aggr, cust, car, hsa, gw
網路邊緣和關係
這個其實蠻容易就可以看出來了,而且透過認識網路邊緣的時候,我們可以知道例如頻寬不夠或是延遲問題的源頭是來自那些邊緣(通常邊緣是一個網路最容易出問題的地方),我們甚至可以看得出ISP和另一ISP之間的關係。ISP互連之間的關係分為三種:
- IP Transit Provider(轉訊)
- Peer(免費互連)
- Customer(提供轉訊服務給其他網路)
通常ISP都會把互連關係也放在路由器名稱裡面,以下是一些例子:
- google.customer.alter.net(很明顯是吧)
- digital.ocean.te0-0-0-13.br03.sin02.pccwbtn.net(這個也很明顯是客戶關係)
- 又或是路由器名稱上面有gw這種標記
通常路由器DNS名稱改變的地點就是網路邊緣
![]()
從這個圖可以看到,從第十二個路由節點到第十三個路由節點,路由器名稱的格式和ISP名字都變了,所以第十二個和第十三個路由節點分別是NTT和PCCW的網路邊緣。或是,你可以看看路由器的名字裡面有沒有包括第三者的名字

從第十個路由節點,我們可以看到路由器名稱夾雜著別人的名字,所以我們又可以說這個是一個網路邊緣。
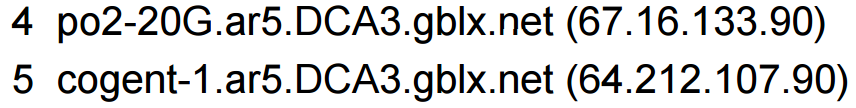
從以上的例子我們雖然可以分辨出網路邊緣,不過我們並看不到一些詳細的資訊。這時候,我們可以試試看這一個路由器介面的另一面:
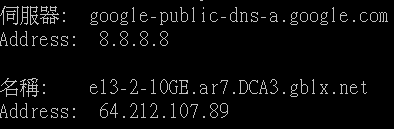
從另一個路由介面,看起來這是一個10Gbps的轉訊來的。只要從另一個角度去看或許會有更多的資訊出現。
認識網路延遲
在網路上,其實有三種事件是會導致延遲的:
- 序列延遲(Serialization Delay)
由於我們要把資料分割成一個個封包去傳送,所以會造成一定程度的延遲。 - 排序延遲(Queuing Delay)
這是因為路由器要把封包排隊傳送出去而造成的延遲。這通常和路由器的線路擠塞由關係,因為如果沒有擠塞,也不會有一個長得會造成顯著延遲的隊伍。 - 傳送延遲(Propagation Delay)
這是由路由器從傳送媒介把封包傳送出去所造成的延遲,這通常是線路或是光/其他傳送媒介的速度的限制。
序列延遲
這種延遲是由傳送封包所產生的延遲。由於封包只能在線路裡面一個一個的傳遞,我們並不能在一個封包還沒傳送好的時候就傳送第二個封包,於是就造成了延遲。不過,這問題在現今的網路越來越少見。隨著時間流逝,網路速度以指數上升,不過封包的大小仍然沒隨著增加,於是封包傳送速度少了,造成的延遲也越來越小。以下是不同的網路速度下傳遞一個封包的時間(假設一個封包大小為1500個位元組):
- 56Kbps - 212.4ms
- T1 (1.536Mbps) - 7.8ms
- 100Mbps - 0.12ms
- 1Gbps - 0.012ms
排序延遲
首先,我們要知道一條線路的使用率到底是什麼一回事。如果我們有一條1Gbps的線路,用掉了500Mbps,我們直覺會說這一條線路的使用率是50%不是嗎?不過在現實,一個網路介面在一瞬間不是在傳輸資料(100%使用率)或是沒資料傳輸(0%使用率),所以我們其實應該說這一條線路在一秒內用掉了50%的容量才對。
而排序在路由器是一個很正常不過的功能,如果當有封包進入路由器的輸入介面,不過他的輸出介面在傳輸資料的時候,路由器一定要等待輸出介面傳輸完畢才可以繼續轉送封包。如果當一個路由器介面到達飽和狀態的時候,封包會被延遲發送的機會就會大幅增加。甚至當一個路由器介面是極度飽和的時候,封包可能會延遲數百甚至數千微秒才會被傳輸出去。
傳送延遲
這種延遲是由傳輸距離所造成的,而我們通常使用光來做長距離傳輸。光在真空的傳輸速度大約是三十萬公里/秒,而光纖的折射率大約是1.48,所以光在光纖裡面的速率就大約是 300,000 * 1 / 1.48 = ~200,000公里/秒。而200,000公里/秒 ~ 200公里/微秒。舉一個例子,光圍繞地球赤道來回跑一次就已經需要400ms了。
如何從traceroute辨認各種延遲因素?
我們到底可以怎麼運用上述的概念辨認各種延遲呢?我們可以首先用路由器名稱上面的位置標記來首先估計它的位置,然後我們就可以從我們猜測出來的這兩個地點的距離計算理論的傳送延遲。以下是一個例子:
8 2 ms 2 ms 2 ms ae-3.r00.tkokhk01.hk.bb.gin.ntt.net [129.250.6.130]
9 3 ms 3 ms 3 ms 63-216-142-1.static.pccwglobal.net [63.216.142.1]
10 22 ms 22 ms 22 ms TenGE0-0-0-0.br01.tap04.pccwbtn.net [63.223.9.74]
19ms就可以從香港去台北?香港和台北距離812公里,所以這延遲其實是合理的。不過…
5 cr2.wswdc.ip.att.net (12.122.3.38) [MPLS: Label 17221 Exp 0] 8 msec 8 msec 8 msec
6 tbr2.wswdc.ip.att.net (12.122.16.102) [MPLS: Label 32760 Exp 0] 8 msec 8 msec 8 msec
7 ggr3.wswdc.ip.att.net (12.122.80.69) 8 msec 8 msec 8 msec
8 192.205.34.106 [AS 7018] 228 msec 228 msec 228 msec
9 te1-4.mpd01.iad01.atlas.cogentco.com (154.54.3.222) [AS 174] 228 msec 228 msec 228 msec從華盛頓去華盛頓竟然要220ms?!別跟我說笑了,這肯定有問題。
路由優先順序和速率限制
要更加理解網路延遲,我們必須要理解現今路由器的基本架構。路由器轉送封包的部分我們稱之為data plane。而這一個部分是有快速路徑和慢速路徑的分別的。快速路徑就是由路由器上的專用硬件來轉送封包,由於不需要路由器的處理器去處理封包,速度很快,而絕大部分的封包都是會經過此路徑轉送出去的。另外的慢速路徑就是當封包需要特別處理的時候才會用到路由器的處理器來應付,我們所發送的traceroute封包和其他特別的封包(IP Options,其他的ICMP封包)都是會走這一條路徑。同時,也會有一些封包是直接傳給路由器的,負責接收這些封包的部分我們叫做control plane。例如用來交換路由表的BGP,用來管理路由器的SNMP,Telnet/SSH等等都是由路由器的control plane負責的。由於路由器並不會常常用到自己的處理器,所以他們的處理器通常處理能力都不是那麼高。以一台可以應付320Gbps-640Gbps流量的路由器來說,他的CPU的速度可能只有600Mhz,而回應我們傳送的traceroute封包並不是路由器的主要考慮。而且很多時候data plane的慢速路徑會和路由器的control plane共用CPU資源,導致當control plane在使用的時候(更新路由表,網管在用SSH管理路由器等等)會影響了路由器回應traceroute封包的時間。這導致了路由器傳送ICMP TTL Exceed的封包的時間增加,而被誤會為網路問題。Cisco IOS有一個很出名的功能叫做BGP Scanner常常導致這些隨機的延遲升幅。
另外,大部分路由器會限制他們產生ICMP封包的速度,以免路由器的CPU被洪水攻擊而受影響。這些限制通常是固定的,在應付大量的traceroute請求的時候可能會超越這一些限制而導致延遲看起來好像升高了。
最重要的是,如果網路真的有問題,在有問題的節點以後的所有節點都會受延遲影響。

以上的例子的第四個路由節點延遲值變了200多ms,然後隨後的節點的延遲值也跟著被影響了,這有機會是網路問題。(註:以上的例子其實並沒有問題,在文章最後說到MPLS的時候你就會知道為什麼了)就算中間的路由節點的延遲值上升了,如果他沒影響隨後的路由節點的延遲,也不太算是網路問題。最差的情況可能是由於回程路由有問題導致的,不過通常都會是剛才說到的路由器限制。
(由於這篇文章太長了,其餘的部分我會放在下一篇文章去介紹。)
已經取得原作者Licson Lee授權轉載
未經允許不得轉載:三號科技報 » 如何正確解讀路由追蹤輸出(traceroute)?
